
In a world where artificial intelligence is increasingly being shaped by a handful of American and Chinese technology giants, one Indian startup is quietly rewriting the rules. Sarvam AI, founded barely three years ago in Bengaluru, has emerged as arguably the most consequential player in India’s sovereign AI story — building large language models from the ground up, training them on Indian languages, and positioning itself at the intersection of national ambition and cutting-edge engineering.
This is not just a story about a startup chasing funding rounds. It is a story about what it means to build AI that belongs to a billion people.
India’s Sovereign AI Champion
In April 2025, the Indian government made a landmark decision: it selected Sarvam AI under the IndiaAI Mission to build India’s first homegrown sovereign large language model. This was not merely symbolic. The IndiaAI Mission, backed by over INR 10,000 crore in government funding, was designed to reduce India’s dependence on foreign AI infrastructure and create a domestic AI ecosystem that reflects India’s linguistic and cultural diversity.
Being chosen as the torchbearer of this initiative placed Sarvam in a unique position — part startup, part national institution. The company’s AI stack was developed to be hosted on-premise within secure, air-gapped infrastructure for sensitive government applications, ensuring Indian data stays on Indian soil. This emphasis on data sovereignty has resonated deeply with policymakers at a time when questions about AI governance and data privacy are dominating global conversations.
In March 2025, the Unique Identification Authority of India (UIDAI) announced a collaboration with Sarvam AI to integrate AI-based voice interactions and multilingual support into Aadhaar-related services — a project that could potentially touch hundreds of millions of Indian citizens. The partnership is a testament to how quickly Sarvam has moved from a research-backed startup to a company with real national-scale impact.
The Models: From Sarvam-1 to 105B
Sarvam AI’s technical journey has been defined by rapid iteration and a willingness to train models from scratch rather than simply fine-tuning existing open-source systems. This distinction matters: fine-tuned models inherit the biases and limitations of their parent, while models trained from scratch on Indic language data can genuinely reflect the nuance and structure of those languages.
Sarvam-1, released in October 2024, was a 2-billion-parameter model supporting 10 major Indian languages — Bengali, Gujarati, Hindi, Kannada, Malayalam, Marathi, Oriya, Punjabi, Tamil, and Telugu — alongside English. It was trained on 4 trillion tokens of an internal dataset. Compact but capable, it signalled that Sarvam was serious about building infrastructure, not just demos.
Then, in February 2026, came the leap that caught the global AI community’s attention. At the India AI Impact Summit in New Delhi, Sarvam unveiled two large language models: Sarvam 30B with 30 billion parameters, and Sarvam 105B with 105 billion parameters using a Mixture-of-Experts (MoE) architecture that activates only about 10.3 billion parameters at a time, dramatically reducing computational costs without sacrificing performance.
The 30B model was pre-trained on approximately 16 trillion tokens of text. The 105B model supports a context window of 128,000 tokens, enabling complex, agentic reasoning across long documents. Both models are open-sourced on Hugging Face under the Apache License — a deliberate choice that signals Sarvam’s commitment to building a developer ecosystem, not locking its technology behind proprietary walls. On Indic language benchmarks, these models often outperform global giants like GPT-4o, Gemini, and Llama-70B.
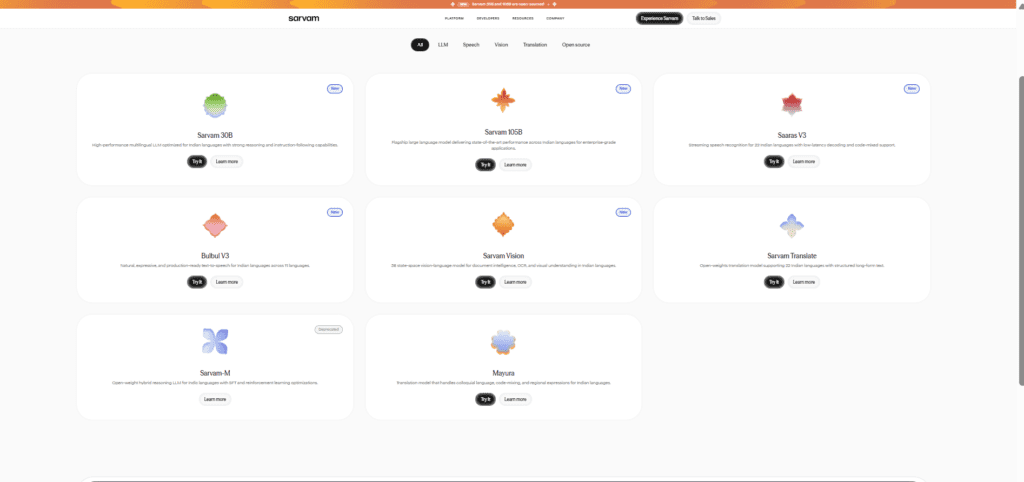
Products Built for Real India
Sarvam AI is not just a research lab — it is a full-stack AI platform designed for deployment at population scale. Its product portfolio reflects a deep understanding of how AI needs to work in the Indian context, where voice is often preferred over text, and where multilingual ability is not a nice-to-have but a necessity.
Bulbul, the company’s text-to-speech model, now supports over 35 voices across 11 Indian languages in its V3 iteration. Sarvam Audio provides automatic speech recognition across 22 Indian languages. Mayura is a translation API that developers can integrate directly into their applications. Vision OCR, launched during Sarvam’s dramatic 14-day product launch streak in early February 2026, scored 84.3% on the olmOCR-Bench — outperforming Google’s Gemini Pro and OpenAI’s ChatGPT on multilingual document understanding.
For enterprises, Sarvam for Work offers specialized coding-focused models and business tools. Samvaad is a conversational AI agent platform built specifically for Indian languages. And in a move that signals Sarvam’s hardware ambitions, the company announced Sarvam Kaze — an AI-powered wearable glasses device that listens, understands, and captures the world through a user’s eyes in real time, supporting over 10 Indian languages. Its launch is expected in May 2026.
The Road Ahead: Promise and Pressure
Sarvam’s journey has not been without scrutiny. Critics point out that while the company’s models are impressive for Indic language tasks, they still operate on a different plane from the frontier models being built by OpenAI, Anthropic, or Google, which are trained on far greater compute, far more data, and refined over years of reinforcement learning. Competing globally at the very frontier remains a capital-intensive challenge.
Yet the company’s approach — frugal engineering, locally optimised models, open-source distribution, and deep government partnerships — may prove to be precisely the right strategy for winning the market that matters most to it: India itself. With a team of around 114 employees and annual revenues of approximately INR 29 crore as of early 2025, Sarvam is lean and focused.
In March 2026, Sarvam launched the Sarvam Startup Program, offering early-stage Indian companies 6 to 12 months of API credits, priority engineering support, and access to production infrastructure — a deliberate effort to seed an ecosystem of developers building on top of Sarvam’s stack. It also introduced Arya, an AI product designed to make business AI more reliable, in February 2026.
Conclusion: More Than a Startup
Sarvam AI represents something more than the sum of its funding rounds, benchmark scores, or product launches. It represents a fundamental argument: that AI should not be a technology that flows down from a handful of powerful Western companies to the rest of the world, but something that can be built from within, shaped by local knowledge, and deployed in service of local needs.
For a country with India’s linguistic complexity, economic diversity, and democratic scale, that argument has profound implications. If Sarvam can continue to execute — securing sustained compute access, retaining top talent, deepening enterprise adoption, and expanding its developer ecosystem — it may well become the proof point that sovereign AI in the Global South is not just possible, but powerful.
Explore More …
In a race defined by scale and capital, Sarvam AI is betting that knowing your people — their languages, their needs, their voice — is the deepest advantage of all.


