
A Friendly Guide to Hugging Face: Understanding Datasets, Models, and Spaces
A Friendly Guide to Hugging Face: Understanding Datasets, Models, and Spaces
If you have been exploring the world of artificial intelligence or machine learning lately, you have probably come across the name Hugging Face — and wondered, “Why does everyone keep talking about it?”
Think of Hugging Face as the GitHub of AI — a place where data scientists, researchers, and developers share machine learning models, datasets, and small apps that anyone can use. It is open, collaborative, and incredibly beginner-friendly.
In this article, we will walk you through the three main building blocks of Hugging Face, which are Datasets, Models, and Spaces and explain how they work together to make AI more accessible. I will also share simple examples to show you how you can use them in your own projects.
What is Hugging Face, Really?
At its core, Hugging Face is an AI community platform — part open-source library, part social hub.
Imagine a place where thousands of developers upload their trained models, where you can find datasets for nearly any AI task, and even run live demos of cool apps all inside your browser.
Whether you are fine-tuning a large language model or creating an image classifier, Hugging Face saves you from starting from scratch. You can reuse what others built, or share your own work with the world.
Here is what the ecosystem looks like in simple terms:
| Component | Description |
| Datasets | Collections of text, images, audio, or video used for training and testing models |
| Models | Pretrained AI systems you can use or fine-tune |
| Spaces | Interactive demos or web apps built using those models |
Datasets – The Foundation of Every Model
In machine learning, data is everything. Without that, your model can’t learn a thing. Hugging face hosts thousands of public datasets from text translation corpora and question-answering benchmarks to speech recognition and image classification datasets.
Example: Loading a Dataset
Let’s say you want to build a question-answering model. Instead of searching the web for random CSV files, you can simply use the datasets library:
from datasets import load_dataset
dataset = load_dataset("rajpurkar/squad")
print(dataset["train"][0])
Output:
{'id': '5733be284776f41900661182', 'title': 'University_of_Notre_Dame', 'context': 'Architecturally, the school has a Catholic character. Atop the Main Building\'s gold dome is a golden statue of the Virgin Mary. Immediately in front of the Main Building and facing it, is a copper statue of Christ with arms upraised with the legend "Venite Ad Me Omnes". Next to the Main Building is the Basilica of the Sacred Heart. Immediately behind the basilica is the Grotto, a Marian place of prayer and reflection. It is a replica of the grotto at Lourdes, France where the Virgin Mary reputedly appeared to Saint Bernadette Soubirous in 1858. At the end of the main drive (and in a direct line that connects through 3 statues and the Gold Dome), is a simple, modern stone statue of Mary.', 'question': 'To whom did the Virgin Mary allegedly appear in 1858 in Lourdes France?', 'answers': {'text': ['Saint Bernadette Soubirous'], 'answer_start': [515]}}With just a few lines of code, you have got the famous SQuAD (Stanford Question Answering Dataset) loaded and ready.
Each dataset comes with helpful metadata (called a dataset card) – describing who created it, what tasks it is used for, and even ethical or licensing notes.
Why Datasets on Hugging Face Are so Useful
- Easy access: Load them in one line of code.
- Community curated: People constantly upload new and specialized datasets.
- Consistent format: Standard fields like
train,test, andvalidationsplits. - Scalable: You can stream huge datasets directly from the hub without downloading gigabytes manually.
If you want to train a Hindi speech recognition model.
You can simply load Mozilla’s Common Voice dataset for Hindi:
ds = load_dataset("mozilla_common_voice", "hi")
print(ds["train"].features)You now have thousands of labeled Hindi audio clips ready to train your model.
Models – The Brains Behind the Magic
Now that you have your data, it is time to make it think. This is where Hugging Face’s Model Hub shines.It’s home to over 600,000 pretrained models built by the community, covering everything from natural language processing to computer vision and audio. Want to summarize text? , translate between languages? . Generate code? Detect objects?. There’s a model for that — and chances are, someone has already trained one that fits your needs.
Example: Sentiment Analysis in One Line
from transformers import pipeline
analyzer = pipeline("sentiment-analysis")
print(analyzer("Hugging Face makes AI so easy!"))
Output
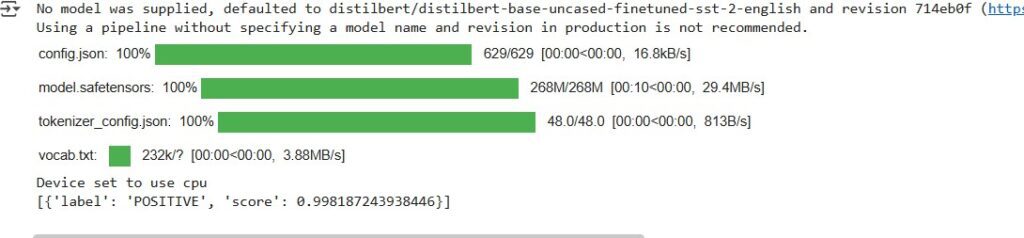
That’s it. In under 10 seconds, you just ran a pretrained transformer model that understands human emotion — no GPU setup or model training needed.This magic works because of the Transformers library, one of Hugging Face’s most popular tools. It gives you direct access to state-of-the-art architectures like BERT, GPT, RoBERTa, T5, and many others.
Fine-Tuning Your Own Model
Let’s say you are working on customer support chat data for your company. You can start with a pretrained model and fine-tune it on your own dataset to make it domain-specific.
from transformers import AutoModelForSequenceClassification, Trainer, TrainingArguments
model = AutoModelForSequenceClassification.from_pretrained("bert-base-uncased", num_labels=2)
# Add your training logic here (tokenization, dataset mapping, etc.)
Once trained, you can upload your model back to the Hugging Face Hub with one line:
model.push_to_hub(“your_name/sentiment-support-bot”)
model.push_to_hub("your_name/sentiment-support-bot")
Now your model is public, documented, and usable by anyone via API or pipeline — a perfect way to showcase your work or power your own app.
Model Licensing & Ethics
Always check the license on each model card before using it commercially.
Some are open (Apache 2.0, MIT), others are restricted to research use only.
Hugging Face Spaces -Bring Your Model to Life
Once your model works, you will want to show it off – maybe to your team, a client, or the world. That is where Hugging Face Spaces come in. Spaces are mini web apps that run right on the Hugging Face Hub. You can create interactive demos using Gradio,Stremlit
Example: Image Classifier App
Suppose you trained a model to identify plant diseases. You can deploy it as a Space using Gradio:
import gradio as gr
from transformers import pipeline
classifier = pipeline("image-classification", model="anoopr/plant-health-model")
def predict(img):
return classifier(img)
gr.Interface(
fn=predict,
inputs=gr.Image(),
outputs=gr.Label(num_top_classes=2),
title=" Plant Disease Detector"
).launch()
Upload this to a new Space on your Hugging Face profile . Your model is live at a public URL like:https://huggingface.co/spaces/your_name/plant-health
Visitors can upload an image and instantly see predictions. There is no need for AWS setup, servers and therefore no extra cost.
Upload this to a new Space on your Hugging Face profile .Your model is live at a public URL like:
https://huggingface.co/spaces/anoopr/plant-health
How Everything Fits Together
Here is a simple way to see how Datasets, Models, and Spaces connect:
| Step | What You Do | Hugging Face Tool |
| 1 | Pick or upload a dataset | Datasets Hub |
| 2 | Train or fine-tune your model | Model Hub |
| 3 | Deploy it for public testing | Spaces |
Let’s make this concrete with a small project idea for ima
# Install dependencies first
# pip install gradio transformers datasets torch pillow
import gradio as gr
from transformers import pipeline
from datasets import load_dataset
# Load a sample image dataset from Hugging Face
# We'll use the 'beans' dataset (3 classes: healthy, angular_leaf_spot, bean_rust)
dataset = load_dataset("beans", split="test[:5]") # Load 5 test images
print("Sample dataset loaded:", dataset)
print("Classes:", dataset.features["labels"].names)
# Load a pretrained image classification model
classifier = pipeline("image-classification", model="google/vit-base-patch16-224")
# Define the function for Gradio
def classify_image(image):
results = classifier(image)
return {res["label"]: float(res["score"]) for res in results[:3]}
# Gradio interface
demo = gr.Interface(
fn=classify_image,
inputs=gr.Image(type="filepath", label="Upload or choose an image"),
outputs=gr.Label(num_top_classes=3),
examples=[sample["image"] for sample in dataset], # show dataset images as examples
title=" Bean Leaf Image Classifier",
description="Predicts the type of bean leaf disease using a pretrained Vision Transformer (ViT) model.",
)
# Launch app
demo.launch()
Run The application :

Output:
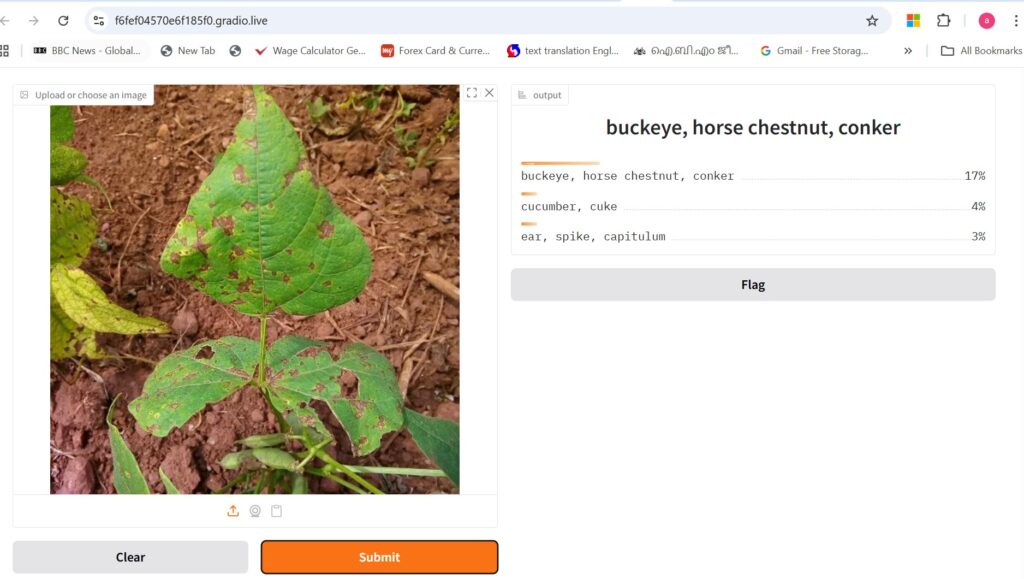
This project demonstrates how to build a simple image classification web application using Hugging Face Transformers, Datasets, and Gradio. The app loads a small sample from the Hugging Face beans dataset, which contains images of bean leaves categorised as healthy, angular leaf spot, or bean rust. A pretrained Vision Transformer (ViT) model (google/vit-base-patch16-224) is used to classify uploaded or sample images. The Gradio interface allows users to upload images or choose example samples to instantly view the model’s top predictions with confidence scores. This lightweight project showcases how to integrate pre-trained deep learning models and public datasets into an interactive web tool .
Why Hugging Face Matters
What makes Hugging Face special is not just the tech – it is the community. Thousands of developers upload models and datasets every week. Researchers share cutting-edge papers with live demos. Also, Small startups and indie creators publish tools that reach millions. It is truly AI built in public. For anyone learning, teaching, or experimenting with machine learning, Hugging Face is the easiest and most inspiring place to start.
Useful Resources

SHARE

