Agentic AI vs Traditional AI Pipelines: A New Software Design Pattern
The software development world is experiencing a quiet revolution. While headlines scream about the latest chatbot features or image generators, something more fundamental is shifting beneath the surface: the way we architect AI systems themselves.
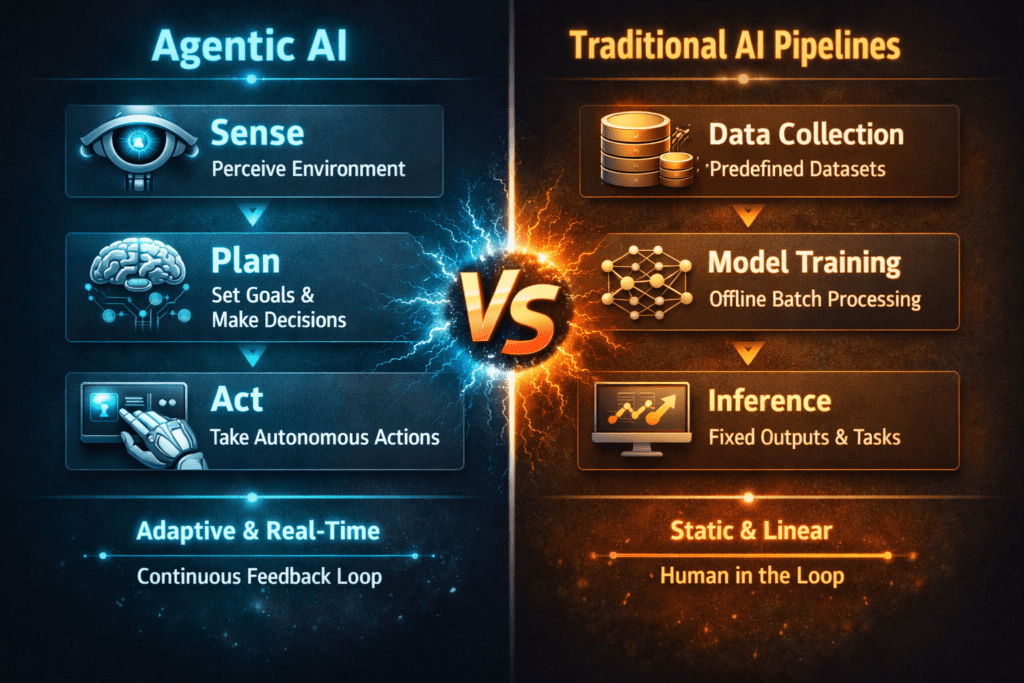
For years, we’ve built AI applications using what I’ll call the “traditional pipeline” approach. You know the pattern—data comes in, gets preprocessed, flows through a model, and spits out a prediction. It’s clean, deterministic, and frankly, a bit boring. But now, agentic AI is flipping this entire paradigm on its head, and the implications for how we design software are profound.

The Traditional Pipeline: Predictable and Rigid
Let’s start with what we know. Traditional AI pipelines are essentially sophisticated assembly lines. You feed in data at one end—maybe customer reviews, medical images, or sensor readings—and out comes a classification, a recommendation, or a forecast. The architecture is linear and the flow is predetermined.
Think about a fraud detection system. A transaction enters the pipeline, features get extracted (transaction amount, location, time of day), the model evaluates these features against learned patterns, and boom—fraudulent or legitimate. The system does exactly what you programmed it to do, nothing more and nothing less.
This approach has served us remarkably well. It’s reliable, testable, and fits neatly into our existing software engineering practices. You can version control your models, A/B test different architectures, and measure performance with clean metrics. Engineering managers love it because it’s predictable. You scope the project, build the pipeline, deploy it, and move on.
But here’s the problem: the world is messy and complex in ways that rigid pipelines struggle to handle. What happens when the fraud pattern changes? What if context matters in unexpected ways? Traditional pipelines don’t adapt—they wait for humans to retrain them with new data.
Enter Agentic AI: The Autonomous Decision-Maker
Agentic AI represents a fundamentally different design philosophy. Instead of building a fixed pipeline, you’re creating an autonomous system that can perceive its environment, make decisions, and take actions to achieve goals. The AI becomes less like a fancy function and more like a colleague you delegate tasks to.
Here’s where it gets interesting. An agentic system doesn’t just process data—it reasons about what to do next. It might call APIs, search databases, run calculations, or even invoke other AI models as needed. The flow isn’t predetermined by you; it emerges from the agent’s understanding of the task.
Imagine that same fraud detection scenario, but with an agentic approach. Instead of a fixed pipeline, you have an agent that understands its goal: determine if this transaction is fraudulent. It might start by checking the transaction against known patterns, but if something seems unusual, it could decide to pull up the user’s recent history, check if the merchant has fraud reports, or even look up whether the IP address is associated with suspicious activity. The agent chooses its own path based on what it learns along the way.
This isn’t science fiction—it’s happening now. Customer service bots that can navigate multiple systems to solve problems. Research assistants that know when to search the web versus when to reason from first principles. Code-writing tools that can debug their own errors and try different approaches.
The Architectural Shift
The difference between these paradigms isn’t just philosophical—it changes everything about how we design systems.
Traditional pipelines are basically pure functions with side effects carefully managed. You design the data flow, optimize each stage, and test the entire pipeline as a unit. Your codebase is structured around transformations: raw data becomes features becomes predictions becomes actions.
Agentic systems, by contrast, are built around control flow and decision-making. You’re defining capabilities (what the agent can do), constraints (what it shouldn’t do), and objectives (what it’s trying to achieve). The actual sequence of operations? That emerges at runtime based on the specific situation.
This is a genuine design pattern shift, similar in magnitude to when we moved from monolithic applications to microservices, or from imperative to declarative programming. The primitives change. Instead of thinking about layers of a pipeline, you’re thinking about tools the agent can use, memory it maintains, and goals it pursues.

The Practical Implications
So what does this mean for developers and architects actually building systems?
First, testing becomes both harder and more important. You can’t just verify that input X produces output Y anymore. You need to test whether your agent makes reasonable decisions across a range of scenarios. Does it know when to escalate to a human? Does it avoid infinite loops? Does it handle edge cases gracefully? This requires a different testing mindset—less unit testing, more integration and scenario testing.
Second, observability takes on new meaning. With traditional pipelines, you instrument each stage and monitor the data flow. With agents, you need to understand the decision-making process. Why did the agent choose to call this API? What was it thinking when it made that choice? Logging and monitoring become less about data metrics and more about decision traces.
Third, the failure modes are different. Traditional pipelines fail when data is malformed or models make bad predictions. Agentic systems can fail in more creative ways—getting stuck in reasoning loops, making poor strategic choices, or misunderstanding their objectives. You’re debugging intelligence, not just code.
When to Use Which Approach
Here’s the thing nobody talks about enough: you don’t always need agentic AI. Sometimes a traditional pipeline is exactly right.
Use traditional pipelines when your problem is well-defined, your data is structured, and the optimal approach is known. If you’re classifying images, forecasting sales, or recommending products based on clear patterns, a pipeline is probably simpler, faster, and more reliable.
Reach for agentic AI when tasks require flexibility, when context matters in complex ways, or when the “right” approach depends on information you’ll only discover during execution. Customer support, research tasks, complex workflow automation—these are agent territory.
The most sophisticated systems will likely blend both approaches. An agent that orchestrates multiple specialized pipelines, or a pipeline that occasionally delegates tricky cases to an agent. The future probably isn’t one or the other—it’s knowing when to use which pattern.
Looking Forward
We’re still in the early days of understanding how to architect agentic systems well. The design patterns are emerging, the best practices are being discovered, and the tooling is evolving rapidly. It reminds me of the early days of cloud computing or mobile development—lots of experimentation, occasional disasters, and gradual convergence toward what works.
What’s becoming clear is that agentic AI isn’t just “AI but better”-it’s a different way of building software. It challenges assumptions about control flow, determinism, and the boundary between code and cognition. For developers, it’s equal parts exciting and unsettling.
The teams that thrive will be those who understand both paradigms and can choose appropriately. Who can build rock-solid pipelines when needed and elegant agents when the problem demands it. Who can test, monitor, and debug systems that think for themselves.
Because that’s what we’re really talking about here: teaching our software to think about what to do, not just execute what we tell it. That’s a new frontier, and the design patterns we establish now will shape the next decade of software development.
The revolution isn’t just in what AI can do it’s in how we architect the systems that wield it.


